Architecture¶
This chapter is aimed at developers who want to understand the underlying concepts and design of swarm.
Swarm hash¶
Introduction¶
Swarm Hash (a.k.a. bzzhash) is a [Merkle tree](http://en.wikipedia.org/wiki/Merkle_tree) hash designed for the purpose of efficient storage and retrieval in content-addressed storage, both local and networked. While it is used in [Swarm], there is nothing Swarm-specific in it and the authors recommend it as a drop-in substitute of sequential-iterative hash functions (like SHA3) whenever one is used for referencing integrity-sensitive content, as it constitutes an improvement in terms of performance and usability without compromising security.
In particular, it can take advantage of parallelisation (including SMP and massively-parallel architectures such as GPU’s) for faster calculation and verification, can be used to verify the integrity of partial content without having to transmit all of it. Proofs of security to the underlying hash function carry over to Swarm Hash.
Description¶
Swarm Hash is constructed using a regular hash function (in our case, Keccak 256 bit SHA3) with a generalization of Merkle’s tree hash scheme. The basic unit of hashing is a chunk, that can be either a leaf chunk containing a section of the content to be hashed or an inner chunk containing hashes of its children, which can be of either variety.
Hashes of leaf chunks are defined as the hashes of the concatenation of the 64-bit length (in LSB-first order) of the content and the content itself. Because of the inclusion of the length, it is resistant to [length extension attacks](http://en.wikipedia.org/wiki/Length_extension_attack), even if the underlying hash function is not. Note that this “safety belt” measure is extensively used in the latest edition of [OpenPGP standard (IETF RFC4880)](https://tools.ietf.org/html/rfc4880). This said, Swarm Hash is still vulnerable to length extension attacks, but can be easily protected against them, when necessary, using similar measures in a higher layer. A possibly very profitable performance optimization (not currently implemented) is to initialize the hash calculation with the length of the standard chunk size (e.g. 4096 bytes), thus saving the repeated hashing thereof.
Hashes of inner chunks are defined as the hashes of the concatenation of the 64-bit length (in LSB-first order) of the content hashed by the entire (sub-) tree rooted on this chunk and the hashes of its children.
To distinguish between the two, one should compare the length of the chunk to the 64-bit number with which every chunk begins. If the chunk is exactly 8 bytes longer than this number, it is a leaf chunk. If it is shorter than that, it is an inner chunk. Otherwise, it is not a valid Swarm Hash chunk.
Strict interpretation¶
A strict Swarm Hash is one where every chunk with the possible exception of those on the rightmost branch is of a specified length, i.e. 4 kilobytes. Those on the rightmost branch are no longer, but possibly shorter than this length. The hash tree must be balanced, meaning that all root-to-leaf branches are of the same length.
The strict interpretation is unique in that only one hash value matches a particular content. The strict interpretation is only vulnerable to length extension attacks if the length of the content is a multiple of the chunk size, and the number of leaf chunks is an integer power of branching size (the fix maximum chunk size divided by hash length).
Two [parallelized implementationd are available in Go](https://github.com/ethereum/go-ethereum/tree/develop/swarm/storage/) is available as well as [a command-line tool](https://github.com/ethereum/go-ethereum/tree/develop/cmd/bzzhash) for hashing files on the local filesystem using the strict interpretation.
Loose interpretations¶
Swarm Hash interpreted less strictly may allow for different tree structures, imposing fewer restrictions or none at all. In this way, different hash values can resolve to the same content, which might have some adverse security implications.
However, it might open the door for different applications where this does not constitute a vulnerability. For example, accepting single-leaf hashes in addition to strict Swarm hashes allows for referencing files without having to implement the whole thing.
Components and layers¶
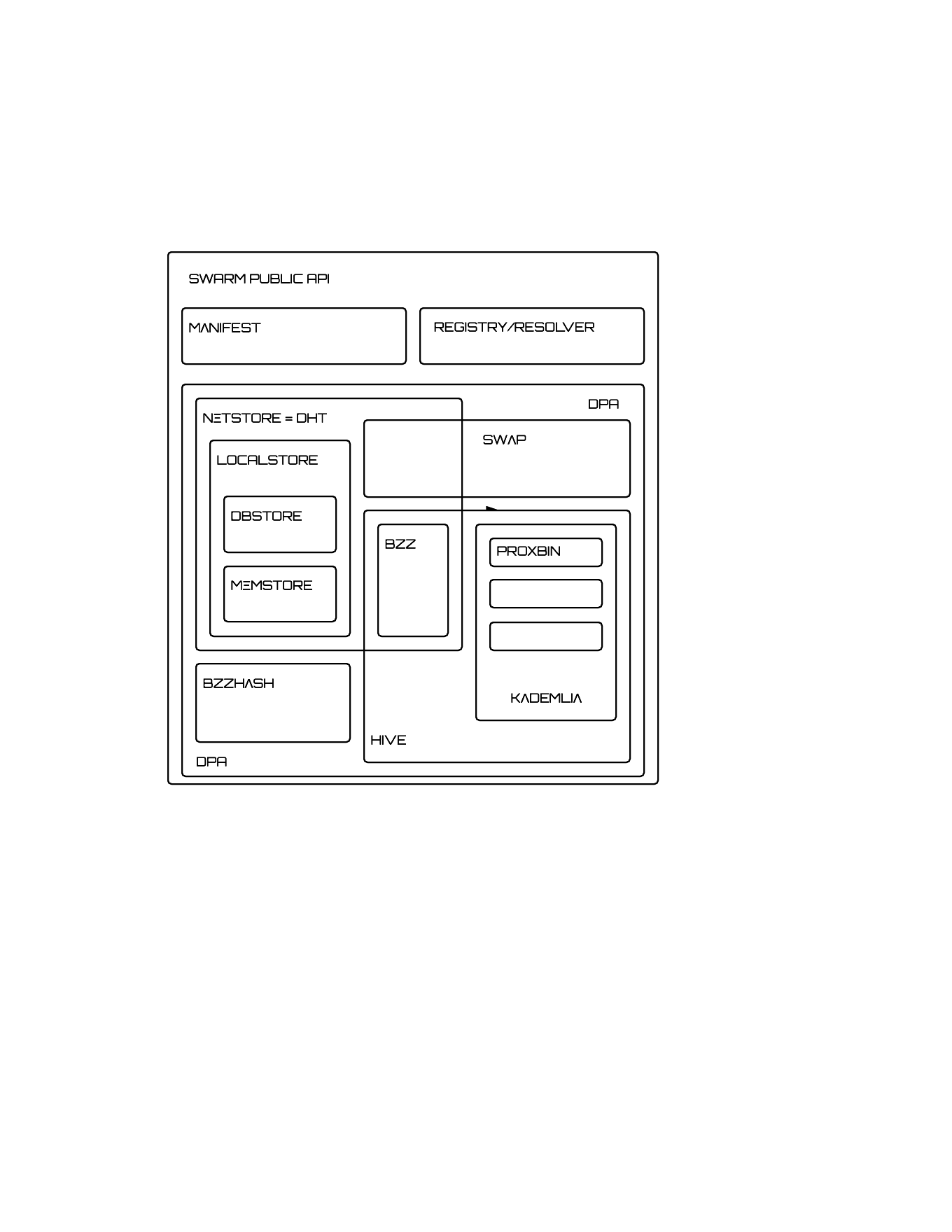
Internal architecture: components of swarm
- MEM memStore
- DBS dbStore
- NET net store
- HASH chunker for bzzhash
- DPA distributed preimage archive
- API the integrated manifest api
- MAN manifest
- DNS registrar: registry + resolver
- BZZ bzz protocol
- BEE a peer that understands the bzz protocol
- KAD kademlia
- HIVE hive
- SWAP the swarm accounting protocol
- SYNC content syncronisation
There are 4 different layers of data units relevant to swarm:
- message: p2p RLPx network layer. Messages are relevant for the bzz wire protocol The bzz protocol.
- chunk: fixed size data unit of storage, content-addressing, request/delivery and accounting: this is the level relevant to the entire storage layer (including localStore, DHT/netstore, bzz protocol, accounting protocol)
- document: in want of a better word, we call the smallest unit that is associated with a mime-type and not guaranteed to have integrity unless it is complete. This is the smallest unit semantic to the user, basically a file on a filesystem. This layer is handled by the DPA and its Chunker.
- collection: a mapping of paths to documents is represented by the swarm manifest. This layer has mapping to file system directory tree. Given trivial routing conventions, url can be mapped to documents in a standardised way, allowing manifests to mimic webservers on swarm. This layer is relevant to high level apis: the go API, HTTP proxy API, console and web3 JS APIs.
The actual storage layer of swarm consists of two main components, the :dfn:localstore (LOC) and the netstore (NET). The local store provides the interface to local computing resources utilised for storage. In particular we explicitly delineate an in-memory fast cache (memory store (MEM)) and a persistent disk storage (dbstore (DBS) possibly with its own cache system). The reason for this is that we can optimise the system by relying on certain properties of the memory store specific for our purpose, e.g., that keys are hashes, so no further hashing is needed, the keys can be directly mapped in a tree/trie structure.
For disk storage, leveldb is used. Both components can easily be swapped by alternative solutions with minimal work.
The netStore is the actual DHT (distributed hash table) implementation. It interacts with the bzz protocol as well as the hive, the network peer logistic manager. The netStore is really where the distributed storage logic is implemented.
The distributed preimage archive (DPA) is the local interface for storage and retrieval of documents. When a document is handed to the DPA for storage, it chunks the document into a merkle hashtree and hands back its root key to the caller (DPA). This key can later be used to retrieve the document in question in part or whole.
The component that chunks the documents into the merkle tree is called the chunker. Our chunker implements the bzzhash algorithm which is parallelizable tree hash based on SHA3/SHA256. The DPA runs a storage loop which receives the chunks back from the chunker and dispatches them to the chunkstore for storage. This entry point is the netStore.
When a root key is handed to the DPA for document retrieval, the DPA calls the Chunker which hands back a seekable document reader to the caller. This is a lazy reader in the sense that it retrieves relevant parts of the underlying document only as they are actually read. This entails that partial reads (e.g., range requests on video) are supported on the lowest level. In other words this scheme provides an integrity protected random access storage of documents.
The swarm manifest is a structure that defines a mapping between arbitrary paths and documents to handle document collections. It also includes various metadata associated with the collection and the documents therein.
The high level API to the manifests provides functionality to upload and download individual documents as files, collections (manifests) as directories. It also provides an interface to add documents to a collection on a path, delete a document from a collection. Additionally, it provides an API for the swarm DNS and Swarm Accounting Protocol (SWAP). The Swarm DNS is name registrar interface allowing for versioned (archival) resolution of domain names as well as registration using ethereum transactions.
API is the go implementation (and go API) for these high level functions. There is an http proxy interface as well as a JS api for these functions. These all differ in there exact functionality due to inherent privilege differences or interface limitations. These are described in detail in API.
There is a simple go HTTP client which can handle the bzz url scheme, it is also exposed in the bzz module (http.get)
The Swarm Accounting Protocol (SWAP) component keeps track of requests between peers and implements the accounting protocol as a response to the swarm incentive system. It is described in detail in Incentivisation.
In what follows we describe the components in more detail.
Swarm Hash (a.k.a. bzzhash, https://github.com/ethersphere/go-ethereum/tree/bzz/bzz/bzzhash) is a Merkle tree hash designed for the purpose of efficient storage and retrieval in content-addressed storage, both local and networked.
In particular, it can take advantage of parallelisms (including SMP and massively-parallel architectures such as GPU’s) for faster calculation and verification, can be used to verify the integrity of partial content without having to transmit all of it. Proofs of security to the underlying hash function carry over to Swarm Hash.
Swarm Hash is constructed using a regular hash function (SHA256 or SHA3) with a generalization of Merkle’s tree hash scheme. The basic unit of hashing is a chunk that can be either a leaf chunk containing a section of the content to be hashed or an inner chunk (non-leaf chunk) containing hashes of its children, which can be of either variety.
Hashes of leaf chunks are defined as the hashes of the concatenation of the 64-bit length (in LSB-first order) of the content and the content itself. Because of the inclusion of the length, it is resistant to length extension attacks, even if the underlying hash function is not. Note that this “safety belt” measure is extensively used in the latest edition of OpenPGP standard. It is, however, important to emphasize that Swarm Hash is obviously vulnerable to length extension attacks, but can be easily protected against them, when necessary, using similar measures in a higher layer. A possibly very profitable performance optimization (not currently implemented) is to initialize the hash calculation with the length of the standard chunk size (e.g. 4096 bytes), thus saving the repeated hashing thereof.
Hashes of inner chunks are defined as the hashes of the concatenation of the 64-bit length (in LSB-first order) of the content hashed by the entire (sub-) tree rooted on this chunk and the hashes of its children.
To distinguish between the two, one should compare the length of the chunk to the 64-bit number with which every chunk begins. If the chunk is exactly 8 bytes longer than this number, it is a leaf chunk. If it is shorter than that, it is an inner chunk. Otherwise, it is not a valid Swarm Hash chunk.
Strict interpretation¶
A strict Swarm Hash is one where every chunk with the possible exception of those on the rightmost branch is of a specified length, i.e. 4 kilobytes. Those on the rightmost branch are no longer, but possibly shorter than this length. The hash tree must be balanced, meaning that all root-to-leaf branches are of the same length.
The strict interpretation is unique in that only one hash value matches a particular content. The strict interpretation is only vulnerable to length extension attacks if the length of the content is a multiple of the chunk size, and the number of leaf chunks is an integer power of branching size (the fix maximum chunk size divided by hash length) [1].
Footnotes
| [1] | Swarm Hash interpreted less strictly may allow for different tree structures, imposing fewer restrictions or none at all. In this way, different hash values can resolve to the same content, which might have some adverse security implications. |
However, it might open the door for different applications where this does not constitute a vulnerability. For example, accepting single-leaf hashes in addition to strict Swarm hashes allows for referencing files without having to implement the whole thing.`
Chunker¶
Chunker is the interface to a component that is responsible for disassembling and assembling larger data. It relies on the underlying chunking model. This module is pluggable, the current implementation uses the Treechunker which implements bzzhash.
When splitting a document, the chunker pushes the resulting chunks to the DPA that delegates them to storage layers (implementing ChunkStore interface) and returns the root hash of the document. After getting notified that all the data has been split (the error channel is closed), the caller can safely read or save the root key. Otherwise it times out if not all chunks get stored or not the entire stream of data has been processed. By inspecting the errc channel the caller can check if any explicit errors (typically IO read/write failures) occured during splitting.
When joining a document, the chunker needs the root key abd returns a lazy reader. While joining, the chunker pushes chunk requests to the DPA that delegates them to chunk stores and notify the chunker if the data has been delivered (i.e. retrieved from memory cache, disk-persisted db or cloud based swarm delivery). The chunker then puts these together on demand as and where the reader is read.
The chunker works in a simple way, it builds a tree out of the document so that each node either represents a chunk of real data or a chunk of data representing an branching non-leaf node of the tree. In particular each such non-leaf chunk will represent is a concatenation of the hashes of its respective children. This scheme simultaneously guarantees data integrity as well as self addressing. The maximum chunk size is currently 4096 which comes from the multiple of configurable parameters :option:Branches and :option:Hash. In addition to the data, the chunk contains the size of the subtree it encodes. Abstract nodes are transparent since their represented size component is strictly greater than their maximum data size, since they encode a subtree.
Distributed Preimage Archive¶
DPA (distributed preimage archive) stores small pieces of information (preimage objects, arbitrary strings of bytes of limited length) retrievable by their (cryptographic) hash value. Thus, preimage objects stored in DPA have implicit integrity protection. The hash function used for key assignment is assumed to be collision-free, meaning that colliding keys for different preimage objects are assumed to be practically impossible.
DPA serves as a fast, redundant store optimized for speedy retrieval and long-term reliability. Since the key is derived from the preimage, there is no sense in which we can talk about multiple or alternative values for keys, the store is immutable.
High-level design¶
DPA is organized as a DHT (Distributed Hash Table): each participating node has an address (resolved into a network address by the p2p layer) coming from the same value set as the range of the hash function. In particular it is the hash of the public key of the swarm node’s base account (an ethereum address given as a command line parameter, defaulting to the first account or coinbase).
There is a distance measure defined over this value set that is a proper metric satisfying the triangle inequality. It is always possible to tell how far another node or another preimage object is from a given address or hash value. The distance from self is zero.
Each node is interested in being able to find preimages to hash values as fast as possible and therefore stores as many preimages as it can itself. Each node ends up storing preimage objects within a given radius limited by available storage capacity. The cryptographic hash function takes care of randomization and fair load balancing.
On a high level, nodes should provide the following services through a public network protocol:
- Inserting new preimages into DPA
- Retrieving preimages from their own storage, if they have it.
- Sharing routing information to a given node address
Locally, in addition to the above, nodes also provide the service of storing and retrieving documents (here, data of any size). When storing, the data is disassembled into a tree of chunks according to the bzzhash scheme. Given the key of the root chunk the data can then can be reassembled with the help of recursively retrieving chunks in the tree.
Requests¶
When receiving a preimage that is not already present in its local storage, the node stores it locally. If the storage allocated by the node for the archive is full, the object accessed the longest time ago is discarded. Note that this policy implicitly results in storing the objects closer to the node’s address, as - all else being equal - those are the ones which are most likely to be requested from this particular node, due to the lookup strategy detailed below.
After storing the preimage, the store request is also forwarded to all the nodes in the corresponding row of the routing table. Note that the kademlia routing makes sure that the row in the close proximity of a node actually contains nodes further out than self thereby taking care of storage redundancy. However, in order to mitigate against node drop out, the preimages, especially those with hashes in the node’s proximity, need to be re-broadcast, albeit with a very low frequency.
When a node received a store request, it remembers it for a while and does not forward the same request. This is needed to avoid redundant network traffic.
Upon receiving a retrieve request if the node has the pre-image, it is returned, called a delivery. Otherwise, the following happens:
- The entire row in the Kademlia table corresponding to the queried hash is returned.
- If routing is deemed not worth the effort (timeout is too short), this fact is also communicated.
- Otherwise, the same query is recursively done and if it succeeds within the specified timeout, the result is sent to the querying node.
Successfully found pre-images are automatically re-inserted into DPA.
A retrieval request for a key arrives with a key recently unseen. It is looked up in local store and if not found, it is assessed if it is worth having, or if its proximity warrants its storage with us or not. If deemed too distant it can be forgotten, if within our storage radius then we open a request entry in the request pool. Further requests in the near future asking for the same key will check its status with this entry.
Immediately upon receiving the request, the target is mapped to its kademlia proximity bin and the peers in the bin are ordered by proximity to the target. We immediately send a response to the initiator containing the first n best peers. The response also indicates if we forward the query and our suggested update to the request timeout.
Simultaneously, take the first connected peer and forward the request with timeout t.
A default time estimate for retrieval is calculated in proportion to the expected hop-distance from the node closest to the queried preimage. If this time is outside of the timeout parameter in the request, the request is not routed/forwarded.
Each node in the row corresponding to the queried preimage is sequentially queried in order of increasing distance from the target hash. The query is forwarded with a timeout value set to the maximum of the above estimate and the total timeout divided by the number of nodes in the row. If the preimage is found or the time elapsed is in excess of the received timeout value, processing of the query is aborted with timeout.
From the set up of the first forward onwards, all retrieval requests of the same target are remembered in a request pool. If we do not receive the data within that window we move on to the next peer. If we receive no delivery within the lifecycle of the request (it is kept alive by the live timeouts of the incoming requests for the content), we consider the item nonexistent and may even keep a record of that.
After successful retrieval, the preimage is stored and the requests are answered by returning the preimage object to all requesting nodes that are active (in terms of being alive connected as well as interested based on their timeout) both forwarding or originator.
The pool of requesting nodes then can be forgotten, since all further queries can be responded with chunk delivery.
Store¶
Deliveries that are unexpected can be considered storage requests.
If a storage request appears for the first time we assess the key for proximity and if deemed too distant may be forgotten. If we want to keep it (which is probably 100% (we just do not forward) then we save it to persistent storage. If the key is found in the database, its expiry may be updated. Storage requests are forwarded to the peers in the same kademlia proximity bin. If we are sufficiently close, the bin might include peers more distant from the peer than we are.
Syncing¶
Node syncronisation is the protocol that makes sure content ends up where it is queried. Since the swarm has a address-key based retrieval protocol, content will be twice as likely be requested from a node that is one bit (one proximity bin) closer to the content’s address. What a node stores is determined by the access count of chunks: if we reach capacity the oldest unaccessed chunks are removed. On the one hand, this is backed by an incentive system rewarding serving chunks. This directly translates to a motivation, that a content needs to be served with frequency X in order to make your worth while storing. On the one hand frequency of access directly translates to storage count. On the other hand it provides a way to combine proximity and popularity to dictate what is stored.
Based on distance alone (all else being equal, assuming random popularity of chunks), a node could be expected to store chunks up to a certain proximity radius. However, it is always possible to look for further content that is popular enough to make it worth while storing. Given the power law of popularity rank and the uniform distribution of chunks in address space, one can be sure that any node can expand their storage with content where popularity makes up for their distance.
Given absolute limits on popularity, there might be an actual upper limit on a storage capacity for a single base address. If this is the case, several nodes should be run in parallel.
This storage protocol is designed to provide an elastic cloud where a growth in popularity automatically scales. An order of magnitude increase in popularity will result in an order of magnitude more nodes actually caching the chunk resulting in fewer hops to route the chunk, ie., a lower latency retrieval.
Now with popularity it may well happen that a node closest to the target address is no longer motivated to keep a chunk. If all the neighbouring nodes have the content, the retrieval may never end up with the closest node and if they themselves happen not to ever retrieve that content, the chunk is deleted. This resembles a doughnot with a whole in the middle. Just as the doughnot grows if more mouth bite at it, need to make sure that it never breaks, no queries from outside end up with the closest nodes which do not have it. Elastic shrinking requires that when a node decides to delete a content it needs to forward it to all nodes closer to it. This in fact indication to the receiving node that subsequent queries may end up being routed to them so they will be rewarded for their delivery.
Smart syncronisation is a protocol of distribution which makes sure that these transfers happen. Apart from access count which nodes use to determine which content to delete if capacity is reached, chunks also store their first entry index. This is an arbitrary monotonically increasing index, and nodes publish their current top index, so virtually they serve as timestamps of creation. This index helps keeping track what content to syncronise with a peer.
When two peers connect, they establish their synchronisation state by exchanging information in the protocol handshake. When a connection is peer connection is opened the first time, syncronisation does not specify an index count, meaning that all content in the relevant address space no matter how long ago it was entered is offered to the peer. The address space relevant by default just designates all addresses that are closer to the receiving node than the source. Syncronisation goes both ways independently. Once all content up to the current index is syncronised, the receiving peer updates the syncornisation state with the current index given by the source node. The source providing a counter should mean that they have provided the recipient with all chunks they have upto that time.
All newly stored content during a live connection is also offered to the peer. Assuming enough bandwidth, peers are expected to be fully in sync meaning that the storage counter stored by the recipient about a source is not very far behind the source node’s current storage count.
In practice all replication of content since the beginning of the peer session is persisted across sessions. This is needed anyway since propagation can overload the connection causing network buffer contention. For a dynamic response, the stream of outgoing store requests are buffered. This means that if there is a disconnection, the earlier backlog will be replayed upon reconnection, ie. offered again to the recipient. Therefore for all intents and purposes synronisation of content for the periods of active connection do not need to be requested. If the recipient updates the counter as given by the source then at disconnection, the syncstate containing this counter will be recorded (LastSeenAt). Next time the peers connect the recipient receives all content stored between this index and the beginning of the session. Since syncronisation can be adjusted by the recipient, it is assumed that syncing state is persisted by the recipient and given in the protocol handshake.
The handshake also allows the recipient to specify an address range by default covering all addresses not further than the peers’ proximity. Note that in the case of peers in the most proximate bin, the target range may contain chunks that are closer to the source than the recipient.
The syncing protocol as defined here subsumes all scenarios where content is pushed. Given all the scenarios a chunk needs to be pushed, we distinguish 5 types:
# Delivery is the responses to a retrieve request (either from originator or forwarded, either locally found or delivered to by other peers). Delivery proceeds typically from nodes closer to the target towards nodes farther from the target. # Propagation new content pushed to us as a result of syncronising with other peers. Propagation typically proceeds from nodes farther from the target to nodes closer to the target. # Deletion if content is deleted, content must be pushed inwards, ie proceeds from nodes farther from the target to nodes closer to the target. # History Delayed propagation of existing chunks prompted by syncronisation in the narrow sense. proceeds from nodes farther from the target to nodes closer to the target. # backlog (clog) is the undelivered chunks buffered at previous sessions
These 5 types are roughly in order of decreasing importance/urgency. The implementation lets you assign independent priorities to these types however we strongly recommend a monotonically decreasing prioritisation. By default, delivery is high priority, propagation types are medium and backlog is low priority. Note that within that priority backlog is replayed respecting the original priorities preserved. Also historical syncing is lower priority than real time traffic so in the default case of propagation, historical syncing only kicks in if no real time high or medium priority chunks available.
In order to reduce network traffic resulting from receiving chunks from multiple sources, all store requests can go via a confirmation roundtrip. For each peer connection in both directions, the source peer sends an unsyncedKeys message containing a batch of hashes offered to push to the recipient. Recipient responds with a delivery request which also contains a batch of hashes that recipient actually needs (does not have) out of the ones listed among the incoming unsynced keys. If no chunks are missing an empty response is possible. Unsynced keys is sent whenever a delivery request is received. If none received until a timeout period and there are outstanding content to push, an unsynced keys message is sent.
Hive is the logistic manager of the swarm. It uses a generic kademlia nodetable to find best peer list for any target. This is used by the netstore to search for content in the swarm. When the node receives peer suggestions (bzz protocol peersMsgData exchange), the hive relays the peer addresses obtained from the message to the Kademlia table for db storage and filtering. Hive also manages connections and disconnections that allows for bootstapping as well as keeping the routing table uptodate. When the p2p server connects with a node capable of bzz protocol, the hive registers the node in the kademlia table and sends a self lookup. A self lookup is basically just a retrieve request with intended target corresponding to the node’s base address (self lookup can be encoded with nil/zero key since peers addr known, and having no request id). The receiving node does not record self lookups as a request or forward it, just reply with peers. This can be improved by simply automatically sending all relevant peers to a connected peer at the time they become known. All peers sent to the connected node are cached so that no repeat sends happen during the session.
Peer addresses¶
Nodes in the P2P network are identified by 256-bit cryptographic hashes of the public key of the base account. The distance between two addresses is the MSB first numerical value of their XOR.
Logarithmic distance and network topology¶
The distance metric \(MSB(x, y)\) of two equal length byte sequences \(x\) an \(y\) is the value of the binary integer cast of \(x^y\), ie., \(x\) and \(y\) bitwise xor-ed. The binary cast is big endian: most significant bit first (=MSB).
Proximity(x, y) is a discrete logarithmic scaling of the MSB distance. It is defined as the reverse rank of the integer part of the base 2 logarithm of the distance. It is calculated by counting the number of common leading zeros in the (MSB) binary representation of \(x^y\) (0 farthest, 255 closest, 256 self).
Taking the proximity order relative to a fix point \(x\) classifies the points in the space (byte sequences of length \(n\)) into bins. Items in each are at most half as distant from \(x\) as items in the previous bin. Given a sample of uniformly distributed items (a hash function over arbitrary sequence) the proximity scale maps onto series of subsets with cardinalities on a negative exponential scale.
It also has the property that any two item belonging to the same bin are at most half as distant from each other as they are from \(x\).
If we think of random sample of items in the bins as connections in a network of interconnected nodes than relative proximity can serve as the basis for local decisions for graph traversal where the task is to find a route between two points. Since in every hop, the finite distance halves, there is a guaranteed constant maximum limit on the number of hops needed to reach one node from the other.
Peer table format¶
The peer table consists of rows, initially only one, at most 255 (typically much less). Each row contains at most \(k\) peers (data structures containing information about said peer such as their peer address, network address, a timestamp, etc). The parameter \(k\) is called bucket size and specified as part of the node configuration.
Row numbering starts with 0. Each row number \(i\) contains peers whose address matches the first \(i\) bits of this node’s address. The \(i+1\) bit of the address must differ from this node’s address in all rows except the last one.
As a matter of implementation, it might be worth internally representing all 255 rows from the outset (requiring that the \(i+1\) bit be different from our node in all rows); but then considering all of the rows at the end as if they were one row. That is, we look at non-y empty rows at the end and treat the elements in them as if they belonged to row \(i\) where \(i\) is the lowest index such that the total number of all elements in row \(i\) and in all higher rows, together is at most \(k\) [2].
Footnotes
| [2] | There is a difference here to the original Kademlia paper http://pdos.csail.mit.edu/~petar/papers/maymounkov-kademlia-lncs.pdf. The rows with a high \(i\) for us here are the rows with a low \(i\) in the paper. For us, high \(i\) means high number of bits agreeing, for them high \(i\) mean high xor distance. |
A peer is added to the row to which it belongs according to the length of the address prefix in common with this node. If that would increase the length of the row in question beyond the bucket size, the worst peer (according to some, not necessarily global, peer quality metric) is dropped from the row, except if it is the last row.
Joining the network requires only one bootstrap peer, all nodes from its table are included in the node’s peer table. Thereafter, it performs a lookup of a synthetic random address from the address range corresponding to rows with indices that are smaller than the row in which the bootstrap node ended up.
Nodes can still safely dump their full peer table and accept connections from naive nodes. Overwriting the entire peer table of a node requires significant computational effort even with relatively low bucket size. DoS attacks against non-naive nodes (as described in this page) require generating addresses with corresponding key pairs for each row, requiring quite a bit of hashing power.
Peer table update¶
GetNodeRecord return one node record with the highest priority for desired connection. This is used to pick candidates for live nodes that are most wanted for a higly connected low centrality network structure for Swarm which best suits for a Kademlia-style routing.
The candidate is chosen using the following strategy. We check for missing online nodes in the buckets for 1 upto Max BucketSize rounds. On each round we proceed from the low to high proximity order buckets. If the number of active nodes (=connected peers) is < rounds, then start looking for a known candidate. To determine if there is a candidate to recommend the node record database row corresponding to the bucket is checked. If the row cursor is on position i, the ith element in the row is chosen. If the record is scheduled not to be retried before NOW, the next element is taken. If the record is scheduled can be retried, it is set as checked, scheduled for checking and is returned. The time of the next check is in X (duration) such that X = ConnRetryExp * delta where delta is the time past since the last check and ConnRetryExp is constant obsoletion factor. (Note that when node records are added from peer messages, they are marked as checked and placed at the cursor, ie. given priority over older entries). Entries which were checked more than purgeInterval ago are deleted from the kaddb row. If no candidate is found after a full round of checking the next bucket up is considered. If no candidate is found when we reach the maximum-proximity bucket, the next round starts.
node record a is more favoured to b \(a > b\) iff a is a passive node (record of offline past peer)
This has double role. Starting as naive node with empty db, this implements Kademlia bootstrapping As a mature node, it fills short lines. All on demand.
The second argument returned names the first missing slot found
The bzz protocol¶
BZZ implements the bzz subprotocol, the wire protocol of swarm. The bzz protocol is implemented as a subprotocol of the ethereum devp2p system. The protocol instance is launched on each peer by the network layer if the BZZ protocol handler is registered on the p2p server.
The protocol takes care of actually communicating the bzz protocol encoding and decoding requests for storage and retrieval, handling the protocol handshake dispaching to netstore for handling the DHT logic, registering peers in the Kademlia table via the hive logistic manager.
The routing implemented by the netstore and communicated via bzz is described in detail in Retrieval. The formal specification of the protocol is given in The bzz protocol.